среда, 14 декабря 2011 г.
среда, 2 ноября 2011 г.
Быстрая сортировка(quicksort, сортировка Хоара)

понедельник, 3 октября 2011 г.
Пузырьковая сортировка

Для понимания и реализации этот алгоритм — простейший, но эффективен он лишь для небольших массивов. Сложность алгоритма: O(n²).
*-Нравится статья? Кликни по рекламе! :)
среда, 14 сентября 2011 г.
Раскраска графа

Рассмотрим математическую модель, используемую для управления
светофорами на сложном перекрестке дорог. Мы должны создать программу, которая в
качестве входных данных использует множество всех допустимых поворотов на перекрестке (продолжение прямой дороги, проходящей через перекресток, также будем
считать "поворотом") и разбивает это множество на несколько групп так, чтобы все повороты в группе могли выполняться одновременно, не создавая проблем друг для друга. Затем мы сопоставим с каждой группой поворотов соответствующий режим работы
светофоров на перекрестке.
*-Нравится статья? Кликни по рекламе! :)
суббота, 3 сентября 2011 г.
Топологическая сортировка
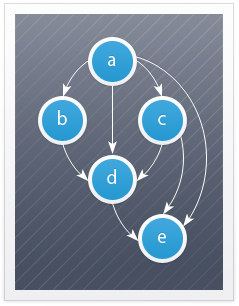
Под топологической сортировкой понимается сортировка элементов, для которых определен частичный порядок, т.е. упорядочивание задано не для всех, а только для некоторых пар элементов.
Задача топологической сортировки графа состоит в следующем: указать такой линейный порядок на его вершинах, чтобы любое ребро вело от вершины с меньшим номером к вершине с большим номером. Очевидно, что если в графе есть циклы, то такого порядка не существует.
*-Нравится статья? Кликни по рекламе! :)
суббота, 27 августа 2011 г.
Связные списки

В информатике, свя́зный спи́сок — структура данных, состоящая из узлов, каждый из которых содержит как собственные данные, так и одну или две ссылки («связки») на следующий и/или предыдущий узел списка. Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.Мы с вами рассмотрим реализацию односвязного (однонаправленного) списка.
*-Нравится статья? Кликни по рекламе! :)
суббота, 30 июля 2011 г.
Бинарные деревья

Бинарное дерево представляет собой структуру, в которой каждый узел (или вершина) имеет не более двух узлов-потомков и в точности одного родителя. Самый верхний узел дерева является единственным узлом без родителей; он называется корневым узлом. Бинарное дерево
с N узлами имеет не меньше [log2N + 1] уровней (при максимально плотной упаковке узлов).
Если уровни дерева занумеровать, считая что корень лежит на уровне 1, то на уровне с номером К лежит 2К-1 узел. У полного бинарного дерева с j уровнями (занумерованными от 1 до j) все листья лежат на уровне с номером j, и у каждого узла на уровнях с первого по j — 1
в точности два непосредственных потомка. В полном бинарном дереве с j уровнями 2j — 1 узел.
*-Нравится статья? Кликни по рекламе! :)
Анализ алгоритма

Что такое анализ?
Анализируя алгоритм, можно получить представление о том, сколько времени займет решение данной задачи при помощи данного алгоритма. Одну и ту же задачу можно решить с помощью различных алгоритмов. Анализ алгоритмов дает нам инструмент для выбора алгоритма.Результат анализа алгоритмов — не формула для точного количества секунд или компьютерных циклов, которые потребует конкретный алгоритм. Из статьи Порядок роста мы уже знаем, что разница между алгоритмом, который делает N + 5 операций, и тем, который делает N + 250 операций, становится незаметной, как только N становится очень большим.
*-Нравится статья? Кликни по рекламе! :)
воскресенье, 19 июня 2011 г.
Алгоритм Прима
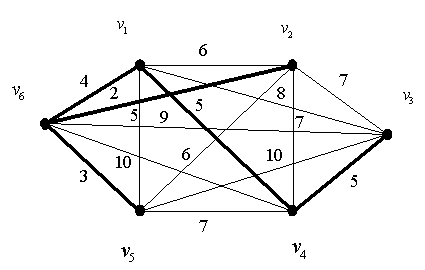
Итак рассмотрим один из простых но очень классических алгоритмов - алгоритм Прима поиска минимальных остовного дерева.
Советую так же ознакомиться со статьей Теория графов и деревьев для Python
Описание
Дан взвешенный неориентированный граф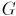 с
с 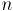 вершинами и
вершинами и 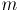 рёбрами. Требуется найти такое поддерево этого графа, которое бы соединяло все его вершины, и при этом обладало наименьшим возможным весом (т.е. суммой весов рёбер). Поддерево — это набор рёбер, соединяющих все вершины, причём из любой вершины можно добраться до любой другой ровно одним простым путём.
рёбрами. Требуется найти такое поддерево этого графа, которое бы соединяло все его вершины, и при этом обладало наименьшим возможным весом (т.е. суммой весов рёбер). Поддерево — это набор рёбер, соединяющих все вершины, причём из любой вершины можно добраться до любой другой ровно одним простым путём.*-Нравится статья? Кликни по рекламе! :)
Теория графов и деревьев для Python
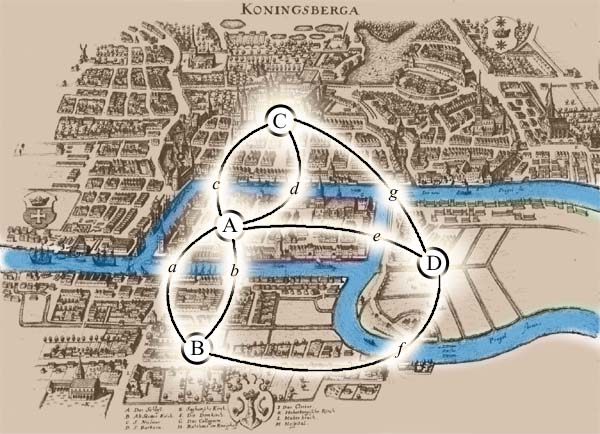
Многие задачи, например, задача обхода точек по кратчайшему маршруту, могут быть решены с помощью одного из мощнейших инструментов — с помощью графов. Часто, если вы можете определить, что решаете задачу на графы, вы по-крайней мере на полпути к решению. А если ваши данные можно каким-либо образом представить как деревья, у вас есть все шансы построить действительно эффективное решение.
Графами можно представить любую структуру или систему, от транспортной сети до сети передачи данных и от взаимодействия белков в ядре клетки до связей между людьми в Интернете.
*-Нравится статья? Кликни по рекламе! :)
суббота, 18 июня 2011 г.
Деревья кодирования по Хаффману

Советую ознакомиться с предыдущей записью: Представление множеств и КодХаффмана
Они применяются к методам представления данных как последовательностей из единиц и нулей (битов). Например, стандартный код ASCII, который используется для представления текста в компьютерах, кодирует каждый символ как последовательность из семи бит. Семь бит позволяют нам обозначить 27, то есть 128 различных символов. В общем случае, если нам требуется различать n символов, нам потребуется log2N бит для каждого символа.
*-Нравится статья? Кликни по рекламе! :)
четверг, 16 июня 2011 г.
Представление множеств
Для понимания идеологии советую прочитать "Свойство замыкания на примере list"
*-Нравится статья? Кликни по рекламе! :)
вторник, 26 апреля 2011 г.
Вложенные отображения

Мы разобрались как создавать абстрагированные последовательности, узнали приемы работы с ними. пришло время отчеркнуть линию и применить знания на примере!
Задача(для тех кто осилил еще и Простые числа вместе с Тест простоты =):
Пусть дано положительное целое число n; найти все такие упорядоченные пары различных целых чисел i и j, где 1 ≤ j < i ≤ n, что i+j является простым.
*-Нравится статья? Кликни по рекламе! :)
понедельник, 25 апреля 2011 г.
Иерархические структуры
*-Нравится статья? Кликни по рекламе! :)
пятница, 22 апреля 2011 г.
Cвойство замыкания, на примере list

Пример взят из Lisp и искусственно спроецирован на Python.
Для реализации конкретного уровня абстракции данных в Lisp имеется составная структура, называемая парой (pair), и она создается с помощью элементарной процедуры cons(мы вместо cons будем использовать кортеж из 2-х элементов). Эта процедура принимает два аргумента и возвращает объект данных, который содержит эти два аргумента в качестве частей. Имея пару, мы можем получить ее части с помощью элементарных процедур car и cdr.
*-Нравится статья? Кликни по рекламе! :)
среда, 20 апреля 2011 г.
Нахождение неподвижных точек функций
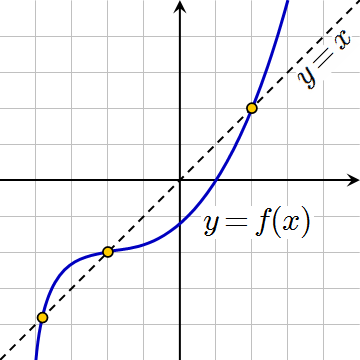
Число x называется неподвижной точкой (fixed point) функции f, если оно удовлетворяет уравнению f(x) = x. Для некоторых функций f можно найти неподвижную точку, начав с какого-то значения и применяя f многократно:
f(x), f(f(x)), f(f(f(x))), . . .
— пока значение не перестанет сильно изменяться.
*-Нравится статья? Кликни по рекламе! :)
Нахождение корней уравнений методом половинного деления

Метод половинного деления (half-interval method) — это простой, но мощный способ нахождения корней уравнения f(x) = 0, где f — непрерывная функция. Идея состоит в том, что если нам даны такие точки a и b, что f(a) < 0 < f(b), то функция f должна иметь по крайней мере один ноль на отрезке между a и b. Чтобы найти его, возьмем x, равное среднему между a и b, и вычислим f(x). Если f(x) > 0, то f должна иметь ноль на отрезке между a и x. Если f(x) < 0, то f должна иметь ноль на отрезке между x и b. Продолжая таким образом, мы сможем находить все более узкие интервалы, на которых f должна иметь ноль. Этот прием мы уже использовали в статье: Двочный (бинарный) поиск элемента в массиве.
*-Нравится статья? Кликни по рекламе! :)
Возведение в степень
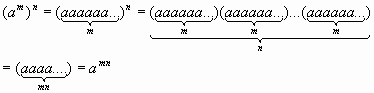

*-Нравится статья? Кликни по рекламе! :)
Порядок роста
*-Нравится статья? Кликни по рекламе! :)
Динамическое программирование: размен денег

- Как дать сдачу определенной суммы, определенным набором монет
- Сколькими способами конь может дойти до определенного места на шахмотной доске.
- И др.....
вторник, 19 апреля 2011 г.
Линейные рекурсия и итерация. Чего не хватает Python

Рассмотрим эти 2 процесса на примере(рассмотренного мной ранее) вычисления факториала. Мы можем вычислить n!, вычислив сначала (n − 1)!, а затем умножив его на n. После того, как мы добавляем условие, что 1! равен 1, это наблюдение можно непосредственно перевести в процедуру. В рекурсивной реализации это выглядит следующим образом.
*-Нравится статья? Кликни по рекламе! :)
Вычисление квадратного корня методом Ньютона

Процедуры очень похожи на обыкновенные математические функции. Они устанавливают значение, которое определяется одним или более параметром. Но есть важное различие между математическими функциями и компьютерными процедурами. Процедуры должны быть эффективными.
В качестве примера рассмотрим задачу вычисления квадратного корня. Мы можем определить функцию «квадратный корень» так:

четверг, 14 апреля 2011 г.
Формулирование абстракций с помощью процедур высших порядков

Тут описана идея, важнейшая для любого программиста. Это то, как должен работать мозг у человека создающего такие вещи, как информационные структуры. Идеология приведена из книги "Структура и интерпретация компьютерных программ", Харольда Абельсона и Джеральда Джей Сассмана.*-Нравится статья? Кликни по рекламе! :)
среда, 13 апреля 2011 г.
Тест простоты

Тест простоты — алгоритм, который по заданному натуральному числу определяет, простое ли это число. Различают детерминированные и вероятностные тесты.*-Нравится статья? Кликни по рекламе! :)
Определение простоты заданного числа в общем случае не такая уж тривиальная задача. Только в 2002 году было доказано, что она полиномиально разрешима. Тем не менее, тестирование простоты значительно легче факторизации заданного числа.
суббота, 9 апреля 2011 г.
Простые числа

Просто́е число́ — это натуральное число, которое имеет ровно два различных натуральных делителя: единицу и самого себя. Все остальные числа, кроме единицы, называются составными.
Простые способы нахождения начального списка простых чисел вплоть до некоторого значения дают Решето Эратосфена, решето Сундарама и решето Аткина.*-Нравится статья? Кликни по рекламе! :)
вторник, 5 апреля 2011 г.
Перевод целых чисел из десятичной системы счисления в двоичную

Тут, конечно писать особо и нечего, просто раз уж показали метод в университете, решил поделиться. Будет продемонстрированно 2 метода: общеизвестный и основанный на логических операциях.
Двоичная система счисления — это позиционная система счисления с основанием 2. В этой системе счисления числа записываются с помощью двух символов (1 и 0).
Сначала, немного применения:
Двоичная система используется в цифровых устройствах, поскольку является наиболее простой и соответствует требованиям:
*-Нравится статья? Кликни по рекламе! :)
понедельник, 4 апреля 2011 г.
Двоичный (бинарный) поиск элемента в массиве

Двоичный (бинарный) поиск (также известен как метод деления пополам и дихотомия) — классический алгоритм поиска элемента в отсортированном массиве (векторе). Используется в информатике, вычислительной математике и математическом программировании.
Частным случаем двоичного поиска является метод бисекции, который применяется для поиска корней заданной непрерывной функции на заданном отрезке.
*-Нравится статья? Кликни по рекламе! :)
Если у нас есть массив, содержащий упорядоченную последовательность данных, то очень эффективен двоичный поиск.
Бинарный поиск позволяет найти данный элемент в отсортированном массиве или определить, что он не встречается в данном массиве за O(log n) действий, где n - количество элементов в массиве.
Описание алгоритма:
- Находится средний элемент последовательности. Для этого первый и последний элементы связываются с переменными, а средний вычисляется.
- Средний элемент сравнивается с искомым значение. В зависимости от того, больше оно или меньше среднего элемента, дальнейший поиск будет происходить лишь в левой или правой половинах массива. Если значение среднего элемента окажется равным искомому, то поиск завершен.
- Одна из границ исследуемой последовательности становится равной предыдущему или последующему среднему элементу из п.2.
- Снова находится средний элемент, теперь уже в «выбранной» половине. Описанный выше алгоритм повторяется уже для данной последовательности.
def BinSearch(li, x):
i = 0
j = len(li)-1
m = int(j/2)
while li[m] != x and i < j:
if x > li[m]:
i = m+1
else:
j = m-1
m = int((i+j)/2)
if i > j:
return 'Нет такого'
else:
return m
Замечательный труд Никлауса Вирта - Алгоритмы и структуры данных, написанный в век, когда любая операция сравнения и перестановки имела огромное значение, описывает модифицированную реализацию метода.В ней мы избавимся от проверки li[m] != x, которая выполняется каждый цикл. Для этого он предлагает отказаться от "наивного" желания закончить поиск сразу после нахождения искомого значения, а дождаться схождения левой и правой границ и сравнить найденный элемент с искомым, поняв нашли или нет. Т.к. всего шагов logN , то он считает это решение целесообразным.
def BinSearchVirt(li, x):
i = 0
j = len(li)-1
while i < j:
m = int((i+j)/2)
if x > li[m]:
i = m+1
else:
j = m
#тут не важно j или i
if li[j] == x:
return j
else:
return None
Вирт пишет, что данный вариант совершает меньше работы, однако мы пренебрегаем вероятностью попадания m на нужный элемент до схождения границ. Поэтому его выигрышность мне сомнительна, но строгого математического обоснования я не проводил.
Двоичный поиск - очень мощный метод. Если, например, длина массива равна 1023, после первого сравнения область сужается до 511 элементов, а после второй - до 255. Легко посчитать, что для поиска в массиве из 1023 элементов достаточно 10 сравнений.
Практические приложения метода:
- Широкое распространение в информатике применительно к поиску в структурах данных. Например, поиск в массивах данных осуществляется по ключу, присвоенному каждому из элементов массива (в простейшем случае сам элемент является ключом).
- Также его применяют в качестве численного метода для нахождения приближённого решения уравнений.
Немножко о производительности
Для сравнения, одухотворения и просто ради полезности, вынес этот вопрос в свою другую статью!)
Использованная литература:
1.) Вики Двоиный поиск
2.) http://younglinux.info/algorithm/dichotomy
3.) http://algolist.manual.ru/search/bin_search.php
Числа Фибоначчи

Чи́сла Фибона́ччи — элементы числовой последовательности*-Нравится статья? Кликни по рекламе! :)
в которой каждое последующее число равно сумме двух предыдущих чисел. Название по имени средневекового математика Леонардо Пизанского (известного как Фибоначчи).
- 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946,…
Более формально, последовательность чисел Фибоначчизадается линейным рекуррентным соотношением:

{kind=link}
{kind=link}
воскресенье, 3 апреля 2011 г.
Вычисление факториала
Мне кажется, что это самый классический алгоритм из существующих. С примером реализации вы наверняка сталкивались и не раз, но для полноты картины, я просто обязан его описать. :))
Факториа́л числа n (обозначается n!, произносится эн факториа́л) — произведение всех натуральных чисел до n включительно:*-Нравится статья? Кликни по рекламе! :)
По определению полагают 0! = 1. Факториал определён только для целых неотрицательных чисел.
.
Алгоритм Евклида

Алгоритм Евклида – это алгоритм нахождения наибольшего общего делителя (НОД) пары целых чисел.
Наибольший общий делитель (НОД) – это число, которое делит без остатка два числа и делится само без остатка на любой другой делитель данных двух чисел.
*-Нравится статья? Кликни по рекламе! :)
Пилотный(нулевой) пост
Итак, это мой нулевой пост в этот блог.
Я надеюсь, что из самого названия понятно, о чем я буду здесь писать.
Скажу сразу, что это вряд ли будут авторские статьи, скорее это будет некая консолидация материалов, которые мне понравились и возможно пригодятся.
Я буду писать где я нашел те или иные статьи, но если вдруг забуду, просьба не бить сильно, а просто указать на это!
Ну вот и все, надеюсь я найду достаточно время, чтобы уделять этому блогу пару часиков в неделю, для пополнения и редактирования.
На сем заканчиваю, надеюсь, самый пустой и бессмысленный пост и приступлю к более серьезному.
Подписаться на:
Сообщения (Atom)